본 포스트는 Hands-on Machine learning 2nd Edition, CS231n, Tensorflow 공식 document를 참조하여 작성되었음을 알립니다.
Index
Introduction of Convolution Operation
Definition of Convolutional Neural Network(CNN)
Back Propagation of CNN
Partice
6. Partice
이 파트는 Convolutional Nerual Network를 직접 구현하는 파트이다. 비단 Convolutional Neural Network 뿐만 아니라 그를 이용한 다양한 현대적인 네트워크 구조들을 구현해 보는 시간을 가지도록 하겠다. 필자의 Deep learning 구현 관련 블로그 포스팅은 전부 Model Subclassing API로 구현될 예정이다. 왜냐? 필자 맘이다 (꼬우면 보지 말든가) 장닌이고, 필자가 생각하기에는 Model Subclassing API의 활용 장점은 확실히 있는 것 같다.
모델을 가독성 있게 관리할 수 있다.
이는 전적으로 OOP에 대한 기본 개념 및 디자인 패턴을 잘 아는 사람에 한에서 그런거다. Vision Transformer쯤 가면 알겠지만, 정말 짜야하는 연산들이 엄청 많다. 그런걸 하나하나 함수로 짜거나 Sequential API로 구성하면 지옥문이 열리게 된다. 아 물론 짜는건 무리가 없겠지만, 유지보수 관점에서는 정말 지옥일 것이다. 그런 의미에서 Model Subclassing API는 원하는 연산을 Class단위로 묶어서 설계하고 그들을 체계적으로 관리할 수 있는 지식이 조금이라도 있다면 (복잡한 디자인 패턴까지는 필요도 없다) 훨씬 가독성이 높은 코드를 짤 수 있다.
Low Level한 연산을 자유롭게 정의할 수 있다.
Model Subclassing API를 사용하면 Custom Layer, Scheduler 등등 여러 연산을 사용자의 입맛에 맞게 정의할 수 있다. 이러면 내가 세운 새로운 가설, 연구 아이디어를 보다 쉽게 구현할 수 있는 판로가 열리는 것이다. 물론 이는 전적으로 자신이 새로운 연산을 구상하고 구현할만한 경지에 도달했을때의 이야기이다.
특히 Pytorch로 소스코드 전환을 비교적 쉽게 할 수 있다.
이건 지극히 필자의 개인적인 생각이다. 필자는 pytorch와 tensorflow를 동시에 써가면서 일을 하고 있다. 모델 개발 및 연구는 pytorch로 배포는 tensorflow를 사용하고 있는데, 모델을 tensorflow로 완전히 포팅해야할 일이 가끔씩 있다. 이때 model subclassing API를 활용하는 편이 소스코드의 구조나 뽄새가 비슷해서 편했던 기억이 난다.
하지만 단점도 명확하게 있다.
못쓰면 이도 저도 안된다.
보면 알다시피, OOP의 기초 지식과 low level로 연산을 정의해서 사용할 수 있는 사람이 아니라면 굳이 Subclassing API를 쓰겠다고 깝치다가 되려 오류만 범할 가능성이 높다.
하지만 필자는 앞으로 잘하고 싶어서 힘든 길을 골라 보았다. 독자들도 이에 동의하리라고 믿는다. (아니면 뒤로 가든가)
사족이 길었는데, 앞으로도 계속 Model Subclassing API만을 사용해서 포스팅을 할 예정이다.
우선, 지난 FCNN처럼 tensorflow 2로 어떻게 CNN layer를 정의할 수 있는지부터 알아보자.
defcall(self, Input): Out = tf.nn.conv2d(Input, self.Kernel, strides=self.Stride, padding=self.Padding) Out = tf.nn.bias_add(Out, self.Bias, data_format="NHWC") return Out
이전에도 설명했듯이 build에서 필요한 Weight를 정의한 뒤에 call에서 그것을 사용한다. 다행이게도 tensorflow에서는 최소한 convolution 연산을 정의해 주었다. 앞으로도 필요한 연산이 있다면 이렇게 정의해 주면 된다.
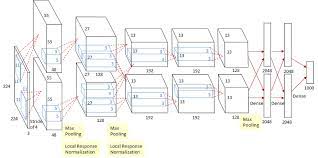
하지만 우리는 굳이 이렇게 convolution layer를 정의해줄 필요가 없다. 왜냐면 tensorflow keras에서 이미 정의되어 있는 좋은 함수가 있기 때문이다. 이에 대한 아주 간단한 사용 예제로써 Alexnet과 ResNet을 구현해 보도록 하겠다. 부록으로 GoogLeNet을 구현한 예제도 있는데, 이는 필자의 Github에 올려 두도록 할테니 시간이 되면 가서 봐 주었으면 한다.
classAlexNet(keras.Model): def__init__(self): super().__init__() # 원래 여기에는 커널 사이즈로 (11, 11)이 들어가고 padding은 valid이다. 하지만 메모리 때문에 돌아가지 않는 관계로 이미지 크기를 줄아느라 부득이하게 모델을 조금 변경했다. self.Conv1 = keras.layers.Conv2D(96, (3, 3), strides=(4, 4), padding="SAME", activation="relu") # LRN 1 self.BatchNorm1 = keras.layers.BatchNormalization() self.MaxPool1 = keras.layers.MaxPool2D(pool_size=(2, 2), strides=(1, 1), padding="VALID")
defcall(self, Input): X = self.Conv1(Input) X = self.BatchNorm1(X) X = self.MaxPool2(X) X = self.Conv2(X) X = self.BatchNorm2(X) X = self.MaxPool2(X) X = self.Conv3(X) X = self.Conv4(X) X = self.Conv5(X) X = self.MaxPool3(X) X = self.Flat(X) X = self.Dense1(X) X = self.DropOut1(X) X = self.Dense2(X) X = self.DropOut2(X) X = self.OutDense(X) return X
자, 필자는 굳이 더럽게 짜 보았다. 왜냐? 이렇게 짤거면 Model Subclassing을 쓰지 말라는 의미로 이렇게 짜 보았다. 진짜 이따구로 짤거면 그냥 Sequential API나 Functional API를 사용하자. 근데 이 정도면 설명이 필요 없을 정도로 그냥 무지성 구현을 시전한 것이다. 그러니 간단하게 Keras의 Conv2D를 설명하고 넘어 가도록 하겠다.
위의 $w_{ijmk}^l$를 우리는 위의 Conv2D 함수로 정의한 것이다. filters는 kernel set의 개수를 의미하며, kernel_size는 Weight kernel의 이미지 크기를 의미한다. padding은 “SAME”과 “VALID”가 있는데, “SAME”으로 하면 알아서 크기를 계산해서 입력 이미지와 출력 이미지의 크기를 같게 만든다. Valid를 선택하면 그냥 padding이 없다고 판단하면 된다.
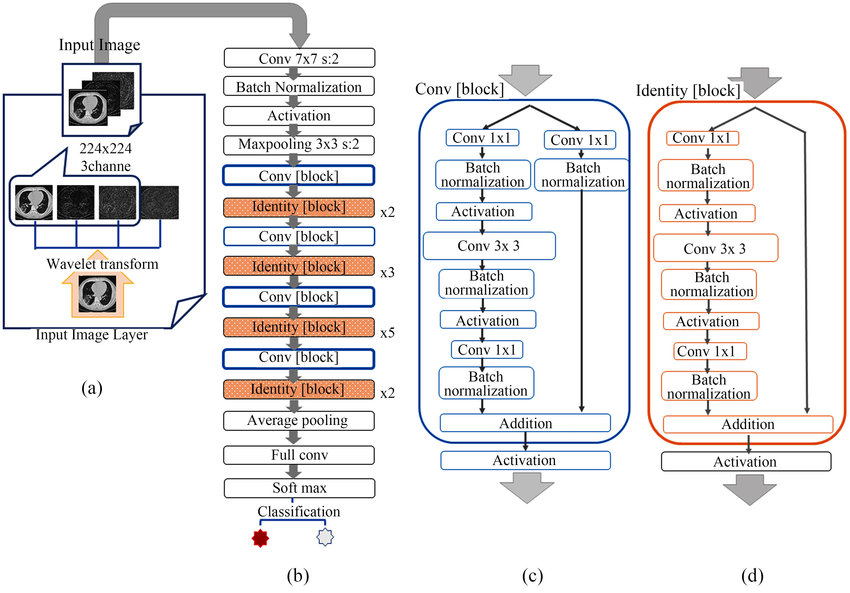
AlextNet에서 대충 Conv2D를 어떻게 사용하는지 감이 왔다면, ResNet을 한번 구현해 보자.
ResNet에 대한 자세한 설명은 다른 포스트에서 정말 이게 맞나 싶을 정도로 분해해서 설명하도록 하겠다. 지금은 그저 다음과 같은 구조가 있구나 정도만 이해하고 넘어가면 된다.
이것이 ResNet50의 구조인데, 2가지 layer를 구현해 보아야 한다. 첫번째는 Conv Block이고 두번째는 Identity Block이다. 하나는 Skip Connection에 Convolution layer를 입힌 것이고 다른 하나는 그렇지 않은 것 뿐이다.
defcall(self, Input): Skip = Input Skip = self.SkipConnection(Skip) Skip = self.SkipBatch(Skip) Skip = self.LeakyReLUSkip(Skip) Z = Input Z = self.conv1(Z) Z = self.Batch1(Z) Z = self.LeakyReLU1(Z) Z = self.conv2(Z) Z = self.Batch2(Z) Z = self.LeakyReLU2(Z) Z = self.conv3(Z) Z = self.Batch3(Z) Z = self.LeakyReLU3(Z) return Z + Skip
defcall(self, Input): X = self.ZeroPadding1(Input) X = self.Conv1(X) X = self.Batch1(X) X = self.ReLU1(X) X = self.ZeroPadding2(X)
X = self.MaxPool1(X) X = self.ResConvBlock1(X) X = self.ResIdentityBlock1(X) X = self.ResIdentityBlock2(X)
X = self.ResConvBlock2(X) X = self.ResIdentityBlock3(X) X = self.ResIdentityBlock4(X) X = self.ResIdentityBlock5(X)
X = self.ResConvBlock3(X) X = self.ResIdentityBlock6(X) X = self.ResIdentityBlock7(X) X = self.ResIdentityBlock8(X) X = self.ResIdentityBlock9(X) X = self.ResIdentityBlock10(X)
X = self.ResConvBlock4(X) X = self.ResIdentityBlock11(X) X = self.ResIdentityBlock12(X)
X = self.GAP(X) Out = self.DenseOut(X) return Out
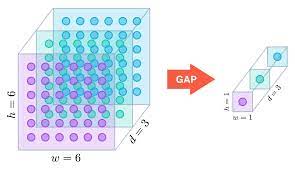
여기서 하나 GAP로 정의된 Global Average Pooling layer가 있다. 이것에 대해서 간단하게만 알아보자.
이 layer는 단순하게 말하자면 feaeture map을 1차원을 만들어 주는 layer이다. 대개, Image는 3차원인데, 차원별로 존재하는 image를 하나의 Scalar 값으로 만든다는 뜻이다. (Global Pooling) 그때, Scalar 값으로 만드는 과정에서 이미지의 각 픽셀 값을 평균을 내는 방법을 취한 것 뿐이다. (Average)
이를 간단히 그림으로 표현하자면 다음과 같다.
그림에서 보여지는 것과 같이, 각 채널에 있는 이미지들의 픽셀값을 평균을 내서 그것을 모으면 채널의 개수 만큼의 크기를 가지는 1-dimensional vector가 완성된다.
여기까지 Convolutional Neural Network의 구현 실습을 마치도록 하겠다. 부디 도움이 되었….을까?는 모르겠지만 재밌게 보았으면 좋겠다.