본 포스트는 해당 링크의 블로그와 논문 “Attention is all you need”를 참조하여 작성되었음을 알립니다.
Index
Attention!Seq2SeqAttention in Seq2Seq
- Transformer Encoder
- Attention in Transformer
- Multi-Head Attention
- Masking
- Feed Forward
- Transformer Decoder
- Positional Encoding
- Partice
- Seq2Seq Attention
- Transformer
여기서는 1은 Part. A이고 2~4는 Part. B에서, 5는 part. C에서 다루도록 하겠다.
Transformer Encoder
자 드디어 대망의 Transformer이다. 현대 Deep learning model의 기초라고도 할 수 있을 만큼 많이 쓰이는 모델이므로 블로그 주제에 선정되었다. 이를 위해서 하고 싶지도 않았던 Attention 공부를 해왔는데, 공부하고 보니 보람 넘치는 시간이었던 것 같다.
Attention in Transformer
우선 Transformer를 제시한 논문의 이름이 “Attention is all you need”라는 것을 파악하고 가자. (필자 생각에는 이때부터 살짝 논문 이름이 제목학원이 된 것 같기도 하다.. ㅋㅋ;;) 한마디로, 기존에 Seq2Seq 같은 경우에는 RNN/LSTM/GRU의 보완제로써 Attention을 사용했다면, Transformer에서는 Attention만을 사용하여 신경망을 구성한다.
![]()
일단, 양산형 블로그글의 클리셰답게, Transformer의 논문에서 Model Architecture의 모식도를 가져와 봤다. 여기에 들어가는 Component를 하나하나 분해해 보면 다음과 같이 정리할 수 있다.
- Multi-Head Attention
- Feed Forward Network
- Masked Multi-Head Attention
- Positional Encoding
- *$N$ ?
- Residual Connection
우리는 이 모두를 하나하나 분해해서 살펴볼 것이다. (5번인 Residual Connection은 다른 Post에서 집중적으로 다루어 볼 것이다.) 그 전에 먼저 Transformer에서 Attention이 어떻게 정의되고 쓰이는지를 알아볼 것이다. 우선, 우리는 Attention을 정의하려면 먼저 $Q$, $K$, $V$를 정의해야한다는 것을 이전 포스트에서 다루었다.
위 행렬의 크기/정의는 어떤 attention이냐에 따라서 달라진다. 이때 attention의 종류는 이전 포스트에서 언급했던 “누가 만든 attention”이냐가 아니라 어떤 식으로 Attention 연산이 이루어 지냐이다. Transformer에서는 아래의 3가지 타입의 attention이 사용된다.
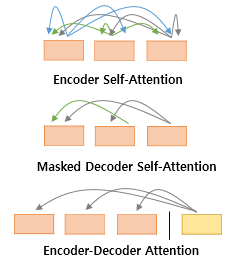
출처: 위 링크에 나와있는 블로그
위 3가지 attention에 따라서 $Q$, $K$, $V$의 출처가 달라진다.
정리하자면 다음과 같다.
Encoder의 Self Attention : Query = Key = Value
Decoder의 Masked Self Attention : Query = Key = Value
Decoder의 Encoder-Decoder Attention : Query : 디코더 벡터 / Key = Value : 인코더 벡터
자, 이제 어떻게 $Q$, $K$, $V$가 정의되는지 파트별로 나눠놨으니 남은 것은 본격적으로 연산에 들어가는 것이다.
그 전에 Transformer에서 사용되는 Hyper Parameter를 먼저 알아보도록 하겠다.
- $d_{model}$ = 512: Transformer의 인코더와 디코더의 입력과 출력의 크기를 결정하는 parameter이다.
- $N$ = 6: Transformer에서 Encoder와 Decoder가 총 몇 개의 층으로 이루어져 있는지를 나타내는 기준이다.
- $H_n$ = 8: Multi head Attention에서 Attention을 병렬로 수행하고 합치는 방식을 사용하는데, 그때 몇개로 분할할지를 결정하는 hyper parameter이다.
- $d{ff}$ = 2048: Transformer의 내부에 Feed Forward 신경망이 존재하는데, 이 신경망의 은닉 unit의 개수를 의미함. 물론, 이 layer의 출력은 당연히 $d{model}$ 이 된다.
Multi-Head Attention
또 양산형 블로그 클리셰답게 논문에 있는 Figure를 가지고 왔다.
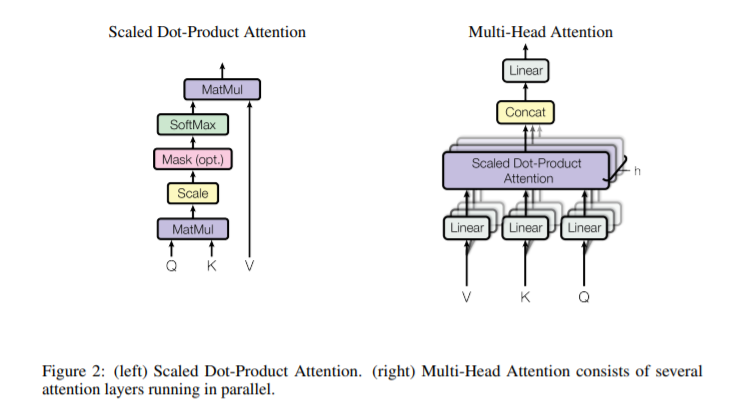
위 그림을 보면서 설명을 읽으면 이해가 잘 될 수 있도록 글을 구성해 보도록 하겠다.
우선 가장 보편적으로 활용되는 자연어 처리를 예로 들고 싶지만, 필자의 성격상 그런 것 보다는 조금 일반적으로 이야기를 하도록 하겠다. 어떤 연속열 데이터 $x1, x_2, x_3 …x_n$ 이 있다고 가정해 보자. 이들 각각이 $x_i \in \mathbb{R}^{d{model}}$ 인 벡터라고 해보자. 자연어 처리라면 Word Embedding으로 생성된 단어 벡터라고 할 수 있고 설령 다른 문제더라도 이것과 비슷하게 representation이 가능하다면 뭐든 학습이 가능하다는 것이다. 이러한 input을 활용해서 $Q$,$K$,$V$를 얻어 보도록 하자.
우리는 3개의 FCNN Layer를 활용해서 입력으로부터 $Q$,$K$,$V$를 얻어낼 것이다.
다음과 같이 FCNN Layer의 Weight를 정의해 보도록 하겠다.
여기서 $dk = d_v = d{model}/H_n$이다. 그리고 sequence length를 $n$이라고 가정하자. 그렇다면 우리는 결과로써 나오는 각 $Q$,$K$,$V$ 행렬의 결과의 크기를 다음과 같다고 생각할 수 있다. 그리고 여기서 $i$는 $1 \leq i \leq H_n$이다. 나중에 각 i별로 병렬로 계산하고 Concatenation을 진행하는 과정을 거칠 것이다. 그래서 Multi Head Attention이다.
이 상태에서 지난 포스트에서 주로 다뤘던 Scaled Dot Attention에 대해서 다시 한번 상기하고, 적용해 보자.
이 Attention의 결과 행렬을 $O_i$라고 했을때, $O_i \in \mathbb{R}^{n * d_v}$이다.
이제 각기 계산한 $O_i$들에 대해서 concatenation을 진행한다. 그 후에 다시 한번 FCNN Layer에 통과시키게 된다.
그렇다면 결과적으로는 다음이 성립한다.
여기까지가 Encoder에 적용시킬 Multi Head Self Attention 이다.
Masking
Masking은 Sequential한 데이터에서 쓸데없는 데이터까지 학습되지 않도록, 또는 원하는 방향으로 데이터를 학습시킬 수 있게 해주는 좋은 도구이다. Transformer에서는 $Q_iK_i^T$룰 계산하면서 나오는 $\mathbb{R}^{n*n}$ 행렬에 적용시키게 된다. 몇가지 예시를 들면서 설명해 보도록 하겠다.
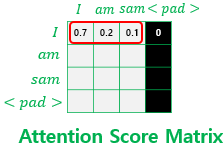
- padding의 학습을 막기 위한 용도 (Padding Mask)
sequence의 길이를 통일시키기 위해, 길이가 모자란 데이터에는 으례 padding을 넣게 된다. 하지만 padding은 실질적인 의미를 가진 데이터가 아니기에 학습에서 배제를 해야한다. 그래서 우리는 $Q_iK_i^T$의 행렬에서 Softmax 함수를 거치기 전에 $-\inf$ 값을 곱하므로써 Attention Distribution에서 Padding에 해댱하는 위치의 값을 0으로 만들어 버린다. 학습에서 배제를 시키는 것이다.
해설이 어렵다면 다음 그림을 보자.
- 자신보다 앞의 데이터를 학습하지 않게 하는 용도
이 Masking은 Decoder에서 사용된다. $Q_iK_i^T$ 행렬에서 자기 자신보다 앞서 있는 데이터를 참조하는 현상이 일어난다. 이는 Transformer가 데이터를 순차적으로 받는 것이 아닌, 한번에 받기 때문에 그런 것이다. 이 문제를 해결하기 위해서 $Q_iK_i^T$ 행렬에 자신보다 앞선 값에는 $-\inf$를 곱해서 Attention Distribution의 값을 0으로 만들어 버린다.
이것도 해석이 어렵다면 다음 그림을 보자.
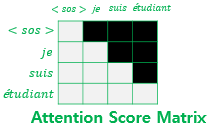
이를 look ahead masking 이라고 한다.
Feed Forward
Transformer에서는 다음과 같은 형태의 FCNN Layer 2개를 겹쳐서 Encoder/Decoder에 사용하고 있다.
위 2개의 $W$행렬은 각 FCNN layer의 가중치 행렬의 크기이다. 이 2개의 FCNN Layer에 사이에 ReLU activation function을 끼워 넣어서 사용한다.
Transformer Decoder
자, 이제 Decoder에 대한 이야기를 해볼 것이다. 하지만 여기까지 읽었다면 Decoder를 굳이 다뤄야 할지도 의문일 정도로 유추하기 쉬워졌다.
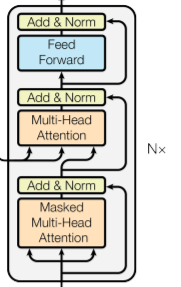
Decoder와 Encoder가 다른 점은 위 그림에서 있는 것이 전부이다.
- 첫번째 Multi Head Attention에서 Look Ahead Masking을 사용했다는점
- 2번째 Multi Head Attention에서 Encoder의 Output을 Key와 Value 행렬로써 사용 한다는점
Residual Connection 특성상, 같은 차원으로 입/출력 행렬이 일괄되기 때문에 위화감 없이 전개가 가능할 것이다. 이 부분은 독자에게 어떤 식으로 연산이 이루어지는지 생각할 시간을 가져보는 것을 추천한다.
Positional Encoding
마자믹으로 Positional Encoding에 대해서 알아볼 것이다. Positional Encoding은 입력의 데이터의 위치 정보를 신경망에 알려주는 한가지의 수단이다. 이것이 필요한 이유는 다양하다. 대표적으로 NLP에서는 어순 또한 언어의 뜻을 이해하는데 중요한 정보이기 때문이다.
대표적인 몇가지 예시를 들자면 다음과 같다.
- Simple Indexing
이는 단순하게 입력이 들어온 순서대로 0, 1, 2, 3, … 의 값을 할당하여 Embedding Layer 같은 것을 거쳐서 벡터로 만드는 방법이다. 가장 단순하지만 딱히 추천하지는 않는다고 한다.
- Sin 함수를 이용한 Positional Encoding
이는 position에 따라서 다음과 같은 수식으로 계산되는 값을 사용하는 방법이다.
이때, $pos$는 Sequence 내에서 입력의 위치를 나타내며, $i$는 Embedding vector 내에서의 위치를 나타낸다.
자세한 것은 다음 그림을 보면 더 자세히 알 수 있다.
![]()
이걸로 기나긴 Transformer의 이야기는 끝났다. 다음 포스팅은 이것을 구현해 보는 시간을 가질 것이다.