본 포스트는 해당 링크의 블로그와 논문 “Attention is all you need”를 참조하여 작성되었음을 알립니다.
Index
Attention!Seq2SeqAttention in Seq2Seq
Transformer EncoderAttention in TransformerMulti-Head AttentionMaskingFeed Forward
Transformer DecoderPositional Encoding- Partice
- Seq2Seq Attention
- Transformer
Partice
이 파트에서는 지난 시간부터 쭉 다뤄온 Attention과 Transformer를 구현해 보는 시간을 가질 것이다. 본격적으로 Model Subclassing API를 제대로 활용하는 시간이 될 것이다.
Seq2Seq Attention
Transformer 구조를 보기 전에 Attention을 Seq2Seq 모델에 적용시켜 보도록 하겠다. 먼저 소스코드부터 보고 가자.
1 | class Attention(keras.layers.Layer): |
우선 우리가 사용할 Attention 구조이다. 지난 Transformer part.A에서 정의한 연산(masking 포함)을 고대로 구현한 것이다.
이를 어떻게 Seq2Seq 모델에 적용하는지는 밑의 그림과 소스코드를 보자.
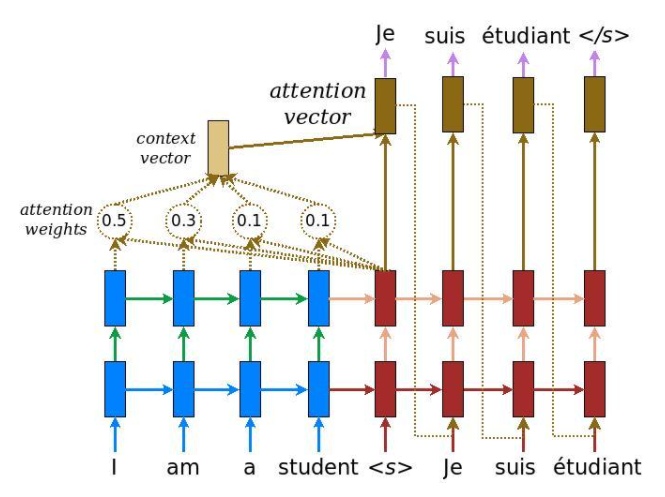
위 그림에 따르면 일단 Seq2Seq는 Encoder와 Decoder가 각기 다른 모델로 있다. 그리고 Encoder에서 나온 모든 time step의 출력과 Decoder의 출력을 같이 사용해서 연산을 해야할 필요가 있다.
필자는 일단 Decoder에 Encoder의 모든 Time step의 출력을 넣는 형식으로 구현을 하였다.
1 | class Encoder(keras.Model): |
소스코드를 보기 전에 Attention의 $Q$, $K$, $V$의 정의를 먼저 상기하고 가자.
$Q$ : 특정 시점의 디코더 셀에서의 은닉 상태
$K$ : 모든 시점의 인코더 셀의 은닉 상태들
$V$ : 모든 시점의 인코더 셀의 은닉 상태들
Encoder에서는 Decoder에서 활용하기 위해서 2개의 출력을 내놓는다. 본인의 출력값과 hidden state의 값이다.
Decoder에서는 Encoder에서의 Hidden state를 입력으로 받아서 자신의 hidden state와 같이 attention! 을 진행한다.
이렇게 만들어진 vector와 마지막 출력 값을 concatenation한 값을 dense에 넣어서 최종적인 출력을 내 놓는다.
이의 training loop를 보면 더 이해가 잘 될 것이다.
1 |
|
Transformer
이제 대망의 Transformer이다. 먼저 Transformer를 구현하기 위해서 어떤 Component들이 필요했는지 알아보자.
- Multi-head Attention
- Positional Encoding
- Encoder Blocks
- Decoder Blocks
우리는 이 4가지 Component들을 각각 순차적으로 구현하고 이를 통해서 최종 모델을 구현할 것이다.
file: model/layer.py
1 | class MultiHeadAttention(keras.layers.Layer): |
각 연산 뒤에 차원을 적어 두었으니 이해하기는 어렵지 않을 것이다. 구체적인 정의가 떠오르지 않을 독자들을 위해서 Multi-Head Attention의 수식을 적어두고 가겠다.
위 수식을 고대~로 구현한 것 밖에 되지 않는다.
그리고 positional Encoding은 다음과 같이 구현했다.
file: model/layer.py
1 | def get_angles(pos, i, d_model): |
이것 또한 정의를 고대로 구현한 것이다. (참 쉽죠?)
이제 Encoder와 Decoder Block을 구현할 차례이다. 귀찮으니 한번에 소스를 적어 두도록 하겠다.
file: model/layer.py
1 | class Encoder(keras.layers.Layer): |
Encoder는 별로 볼게 없고, Decoder를 보자면 지난번 정의에서 다뤘듯이, 첫번째 Multi-Head Attention과 두번째 Mutli-Head Attention은 다른 입력이 주어지고, 다른 masking이 주어진다.
따라서 Decoder의 입력으로 출력 sequence, encoder 출력, look ahead masking, padding masking이 들어가야 한다.
자세한 정의는 part.B를 다시 참고하자.
참고로, masking은 다음 함수로 만들었다.
file: model/model.py
1 | def create_padding_mask(seq): |
그리고 최종적으로 이렇게 만든 Encoder, Decoder Block을 쌓아서 Transformer 모델을 만들어야 한다.
편의상, Encoder모델, Decoder 모델을 만들고 이를 하나로 합쳐서 Transformer 모델을 만들었다.
file: model/model.py
1 | class EncoderModel(keras.Model): |
그리고 Transformer에서 보면 Embedding layer를 사용하는데, 이는 Dense와 결과적인 측면에서는 다를 것이 없디. 하지만 token을 vector로 Embedding하는데 있어서 훨씬 효율적이니 되도록 token을 vector로 임베딩할때 이걸 사용하도록 하자.
각 Encoder와 Decoder는 num_layer(hyper parameter)만큼 Encoder, Decoder 블록을 반복해서 쌓고, 그것들을 차례로 출력으로 내놓는다. 이제 2개를 합쳐서 간단하게 Transformer 모델이 완성되는 것이다.
이쯤되면 필자들도 느낄 것이다. 이럴때 Model Subclassing API가 빛을 발휘한다. 이 각각의 Component들을 함수로만 구현하는 것 보다는 class로 묶어서 관리하는 것이 가독성, 유지보수 측면에서 훨씬 이득이다.
그리고 논문에 의하면, Transformer는 독자적인 learning rate scheduler를 가진다. 이 수식은 다음과 같다.
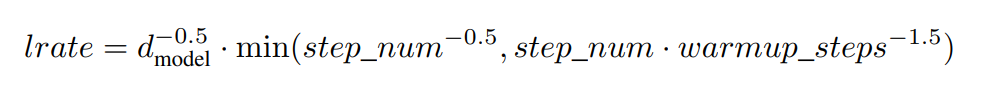
이를 구현하기 위해서 다음과 같이 Custom Scheduler를 만들 수 있다.
file: model/model.py
1 | class CustomSchedule(keras.optimizers.schedules.LearningRateSchedule): |
여기까지 구현하면 Transformer의 구현은 끝이 난다. 굳이 여기서는 Training loop까지는 다루지 않겠다. 한번 필자가 직접 완성해 보도록 하자. 정 모르겠다면 필자의 github에 완성판이 있으니 직접 가서 찾아 보기를 바란다.