본 포스트는 블로그와논문 “An Image is Worth 16x16 Words: Transformers for iamge recognition at scale”을 참조하여 작성되었음을 알립니다.
Index
- CNN의 종말
- Vision Transformer의 구조
- ViT Inspection
- Embedding Filters
- Positional Encoding
- Attention Distance
- practice
여기서는 1~2은 Part. A이고 3는 Part. B에서 다루도록 하겠다.
CNN의 종말
그렇다. 자연어 처리에서 큰 활약을 보여주던 Transformer는 Vision 영역에도 침범한 것이다. 필자가 이 논문을 처음 보았을때 느꼈던 감정은 아쉬움이었다. 마치 떠나보낸 옛 애인같은 느낌이랄까..? 무슨 헛소리냐 느낄텐데, 고딩학생때부터 필자는 CNN에 미친듯이 시간을 할애하였기에 (필자의 CNN 포스팅 내용은 고딩때 정리한 것을 조금 다듬어서 쓴 것이다. 심지어 그걸 C++로까지 구현했으니 말 다했다 ㅋㅋ;;) 이제 기술의 진보가 내가 가장 아끼던 도구를 구식 취급하는 것이다. 하지만 동시에 온 몸에 전율을 느끼기도 하였다. 시대가 흐른다는 것을 몸소 느끼고 있었기 때문이다.
각설하고, CNN은 Vision 분야에서 Transformer에 비해 다음과 같은 패배 요인이 있다.
“CNN은 공간적인 정보를 Encoding하는데 실패했다.”
이게 머선 소리냐? CNN은 Filter를 학습해서 정보를 습득하였는데, 그것들 간의 연결점이 없다는 것이다. 이를 비유적으로 표현한 그림이 다음과 같다.
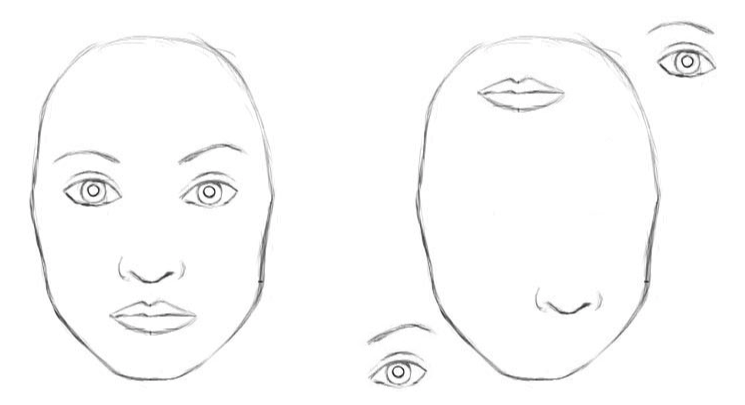
위 그림은 CNN의 관점으로 왼쪽이나 오른쪽이나 별반 다를게 없다. 이러한 부분이 CNN이 transformer에 밀리게 되는 요인이 되었다.
이 과정에 대해서는 다다음 파트에서 자세히 알아보도록 하자.
Vision Transformer(ViT)의 구조
우선 논문에서 제시하는 ViT의 구조를 보자.
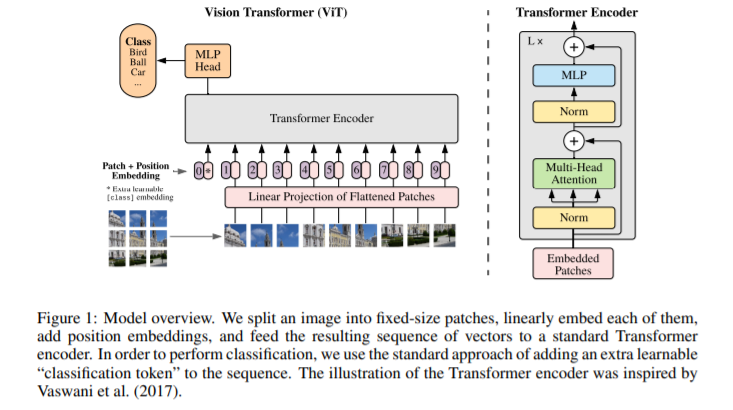
간단하게 요약하면 다음과 같다.
- Image를 일정 크기의 Patch로 분할한다.
- Image를 Flatten하고 FCNN Layer에 거쳐서 일정 크기의 벡터로 만든다.
- Positional Encoding과 함께 Encoder-Only Transformer에 넣는다.
- 결과를 MLP에 넣고 Classification한다.
참 쉽죠?
여기까지만 보면 매우 간단하다. 물론 Transformer를 알고 있다는 가정 하에.
따라서 필자도 그렇게까지 자세히 파고 들지는 않고 딱 논문에 나와 있는 수준으로만 구조 분석을 하도록 하겠다. 참고로 이번 포스트 시리즈에서는 딱히 성능 분석은 하지 않고 구조만 분석하고 구현하는 것을 목표로 할 예정이다. 필자는 아직 공부중인 학생이기에 너무 많은걸 목표로 하기 보다는 일단 연산을 똑바로 파악하고 구현하는 것 부터 하는 것이 정도라고 생각한다.
해당 논문에는 매우 친절하게 모델 구조에 대한 수식이 그대로 나와 있다.
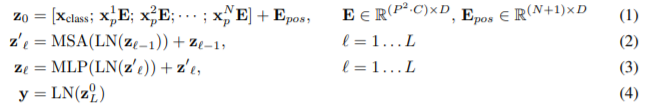
앞선 Transformer 포스트를 읽고 왔다면 이해가 한층 쉬울 것이다. 다만 몇가지만 부연 설명을 하고 자세한 것은 part.B에서 다루도록 하겠다.
- $x_{class}$는 BERT에서 사용되는 것과 똑같은 token이다. 이의 구현 방법은 part.B에서 더욱 자세히 다루어 보도록 하겠다.
- 각 Image Patch들은 1 개의 FCNN layer를 거치게 된다. 이때, Bias는 없다.
- 위 표기 중에 $LN$은 Layer Normalization의 약자이다.
- Encoder를 $L$번 반복하고 나온 결과를 MLP에 넣는다.
- 최종 결과에 다시 한번 Layer Normalization을 진행한다. 이때, sequence의 마지막 Component만을 가져와서 진행한다.
구조만 놓고 보자면 Transformer만 안다면 전혀 어려운 것이 없다. 다만 구현이 조금 복잡하니 다음 part에서 자세히 다루어 보도록 하자.
ViT Inspection
양산형 블로그답게, 논문에 있는 내용을 한번 정리해 보도록 하겠다. 밑의 사진은 크게 ViT를 3가지 측면으로 분석한 것에 대한 Figure이다.

Embedding Filters
논문의 저자들은 먼저 첫번째로 들어가는 layer에서 Image Patch를 Linear Embedding하는 Dense Weight를 분석해 보았다.
그 결과 위의 맨 왼쪽의 사진처럼 보였다는 내용이다. 하지만 이로써는 그럴듯하게 보이는 기저 함수와 비슷하게 보일 뿐이라고 한다. 필자가 보기에도 이걸로 뭔가를 더 해석하기에는 비약이 너무 심하다고 생각한다.
Positional Encoding
그 후에 논문의 저자들은 Positional Encoding Layer의 Weight를 조사했다. Part.B에서도 다루겠지만, 여기서의 Positional Encoding은 learnable한 weight이다. 이를 시각화 한 것이 위의 사진에서 중간 사진이다. 어떻게 시각화 한 것이냐면, 사진의 각 patch들은 7 7의 크기인데, 해당하는 position의 patch에 대해서 다른 모든 patch들과 cosine similarity를 구한 것이다. 그래서 7 7 크기의 그리드에 사진들이 붙어있는 것이다.
위 그림에 따르면
- 각자 자기 자신의 위치 근처에서 Cosine Similarity가 높다.
- 또한 같은 열/행일 수록 유사도가 높다는 것 또한 알 수 있었다.
- 그리고 가끔씩 큰 그리드에서 측정하면 sin파동 구조가 발생하였다.
그리고 저자들의 추가적인 연구에 의해서 2D Positional Encoding을 수행했을때는 성능의 Improvement가 없었다.
이 4가지 사실을 종합해 보았을때 저자들은 position embedding이 image의 2차원 공간 정보의 형상을 학습할 수 있다고 결론을 지었다.
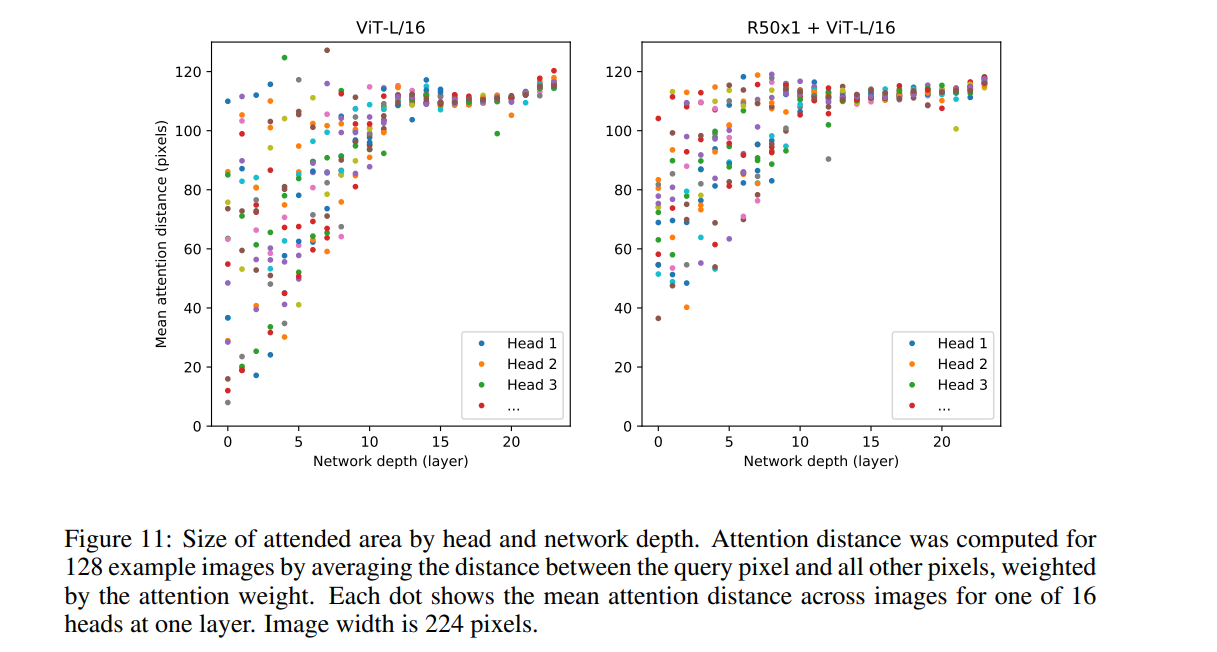
Attention Distance
Encoder의 Self-Attention 구조는 얕은 층에서도 Image의 전체적인 정보를 통합하게 해준다. (Attention의 구조상 한개의 층에서도 전체적인 정보를 통합시켜주니깐) 저자들은 각 층별로 나온 Attention Distribution를 이용하여 그들을 Weight로 각 Image Patch들의 Pixel 값들의 차이의 평균을 구하였다.
그 결과, 네트워크의 깊이가 깊어질수록 분산은 적어지고 값은 높아지는 것을 확인하였다. 또한 이러한 특성상, 얕은 층의 attention layer들에서 일부 head에 대해서도 높은 attention distance를 보인다. 즉, 얕은 층에서도 전체적인 이미지의 정보를 어느 정도는 통합하고 있었다느 말이 된다.
저자들은 논문 “Quantifying Attention Flow in Transformers
“에 나온 방법을 통해서 Attention score를 input token에 적용하여 계산해본 결과, 꽤나 국지적으로 분류에 의미있는 결과를 얻어낼 수 있었다고 한다. 다음 그림과 같이 말이다.

필자도 얼추 이해만 하고 글을 작성하는 것이라 틀린 부분이 있다면 언제든 지적 부탁한다.