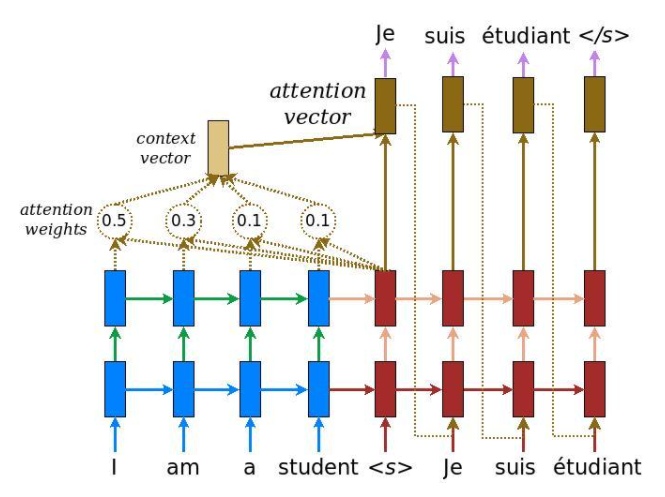
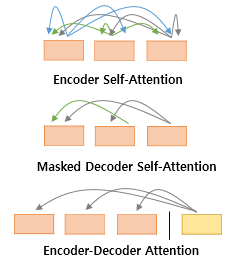
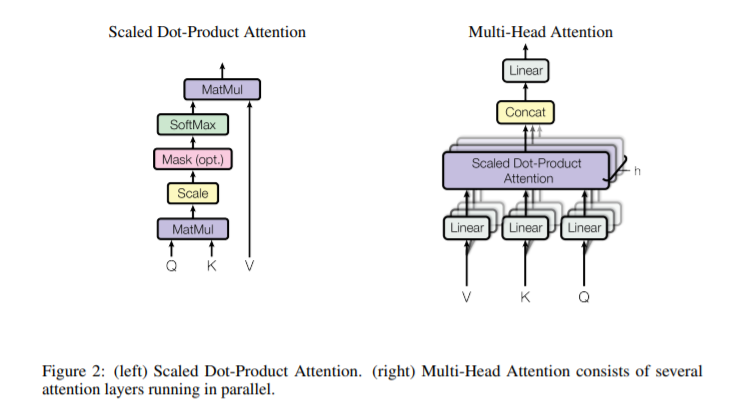
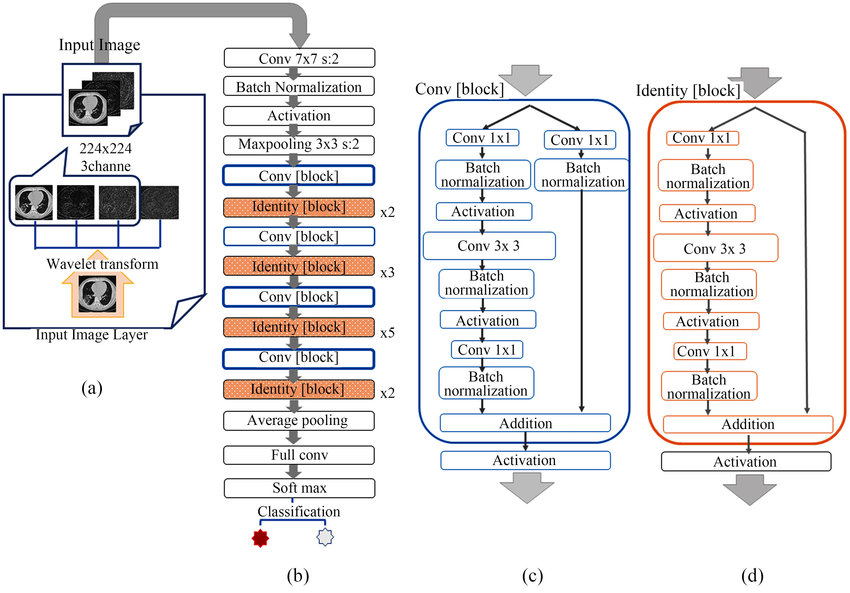
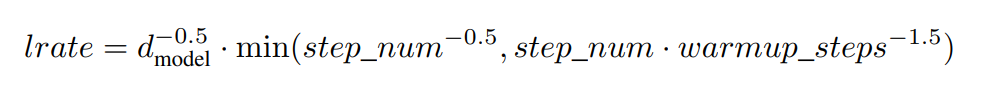본 포스트는 Hands-on Machine learning 2nd Edition, CS231n, Tensorflow 공식 document, Pattern Recognition and Machine Learning, Deep learning(Ian Goodfellow 저)을 참조하여 작성되었음을 알립니다.
Index
- Essential Mathematics
- Basic of Bayesian Statistics
- Information Theory
- Gradient
- Loss Function Examples
- What is Optimizer?
- Optimizer examples
- Partice
여기서는 1~4는 Part. A이고 5는 Part. B에서 다루도록 하겠다.
Essential Mathematics
Basic of Bayesian Statistics
이 파트에서는 Bayesian Statistics에 대해서 매~우 간단하게 다루어 보도록 하겠다. 실은 다룬다고 말하는 것도 부끄러울 정도록만 할 예정이니 너무 기대는 하지 않아 주었으면 한다.
여기서는 조금 익숙하지 않은 통계학, Bayesian 통계학을 소개하도록 할 것이다. 이 분야는 패턴 인식에서 아주 많이 활용되며, 기존의 확률론에 익숙해져 있다면 이를 받아들이기 매우 힘들다.
우선, “확률”이란 무엇인지에 대해 논하고 넘어가자.
Frequentist – “빈도”에 대한 척도, 어떤 일이 앞으로 얼마나 일어날 수 있겠는가?
Bayesian – 불확실성에 대한 척도, 이 가설에 대해 얼마나 확신할 수 있는가?
Bayesian 관점에서의 확률을 그림으로 표현하자면 대충 아래와 같다
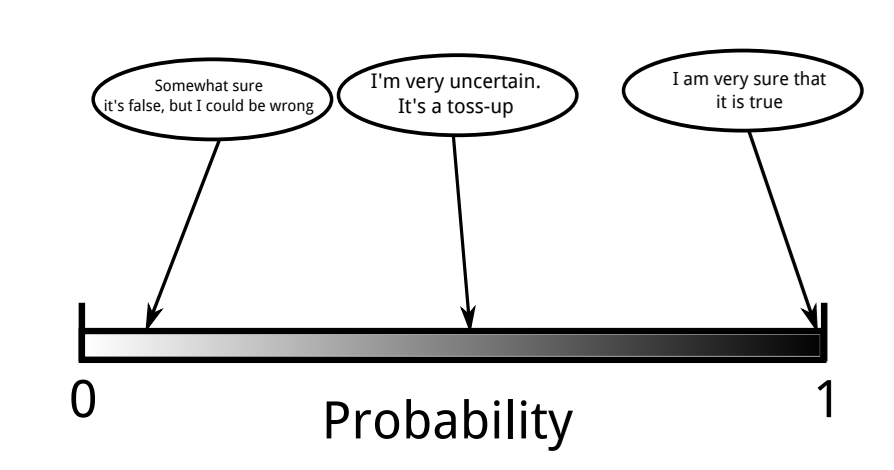
간단하게만 말하자면, 확률이 1에 가까울수록 “명제의 참에 대한 확신”을 가질 수 있고 0에 가까울 수록 그 반대인 것이다. 그리고 0.5에 가까워 질수록 점점 애매해 지는 것이다.
그리고 이 관점에서 우리는 다음 3가지 개념을 다뤄 볼 것이다.
- Prior Probability
- Likelihood
- Posterior Probability
이 3가지를 말로 풀어서 설명하면 다음과 같다.
- Prior Probability: 데이터가 주어지기 전에 우리의 가설은 얼마나 타당한가?
- Likelihood: 어떤 데이터들이 특정 확률 분포에서 추출되었을 확률
- Posterior Probability: 주어진 데이터에 한에서 우리의 가설이 얼마나 타당한가?
우리는 이들애 대해서 엄밀한 정의를 다루는 것이 아닌, 좀 더 실용적인 측면에서 예제와 함께 다루어 볼 것이다.
이를 활용하는 예제로써 한번 Curve fitting 문제를 생각해 보자. Curve fitting을 하기 위해서 우리는 어떤 parameter $w$를 가지고 이를 우리가 원하는 곡선에 맞게 fitting하는 과정을 거칠 것이다.
우리는 이때 이런 가정을 할 수 있다.
“parameter $𝑤$로 생성된 곡선 $𝐶$는 주어진 데이터 $𝐷$를 잘 설명할 수 있다.”
이 문장은 특정한 불확실성을 가지고 있다. 당연히 처음부터 Fitting이 잘 될 리도 없고, 특정한 에러를 가지고 있음이 분명하다.
이렇다면 우리는 그 불확실성을 어떻게 확률로 표현 가능하겠는가? 한번 다음과 같이 해보자.
$Pr(w)$: 데이터가 주어지기 이전에 위의 가설이 얼마나 확실한가
$Pr(D|w)$: 주어진 모델에서 데이터가 얼마나 잘 설명되는 가의 척도
$Pr(w|D)$: 데이터가 주어졌을 때, 이 모델이 데이터를 잘 설명하는 가의 척도
이때, 좋은 모델을 만드는 방법은 크게 2가지가 있다.
- Likelihood를 최대화하는 parameter 만들기 ==> MLE(Maximum Likelihood Estimation)
- Posterior Probability를 최대화하는 parameter 만들기 ==> MAP (Maximum A Posterior)
즉, 1번 방법은 최대한 좋은 주어진 모델에서 최대한 좋은 데이터의 설명을 얻어내는 방법이고, 2번 방법은 데이터를 가지고 최대한 좋은 모델을 얻어내는 방법이다.
이 관점에서 1번부터 차근차근 설명해 보도록 하겠다. 어떻게 하면 likelihood를 최대화할 수 있을까?
우선 $Pr(D|w)$의 함수를 찾아서 이를 최대로 만들어 주면 되는 것이다. 최대로 만들어 주는 방법은 여러가지 방법이 있겠지만, 우선 그것보다 $Pr(D|w)$를 찾는 것부터 진행하는 것이 순서일 것이다.
그 전에 표현을 좀 정리하고 가겠다.
자, 그리고 우리는 다음과 같이 “가정”을 해보자.
데이터에서 주어진 target값과 우리의 예측 값의 차이가 Gaussian Distribution을 따른다
이를 수식으로 표현하면 다음과 같다.
여기서 $\epsilon_i$는 실측값과 데이터 간의 오차이다. ($\epsilon_i = t_i - y(x_i;w)$)
즉, 우리가 고등학교에서 확률과 통계를 착실히 배웠다면 다음과 같이 변형이 가능할 것이다.
위의 내용을 시각화 하면 대충 다음과 같다.
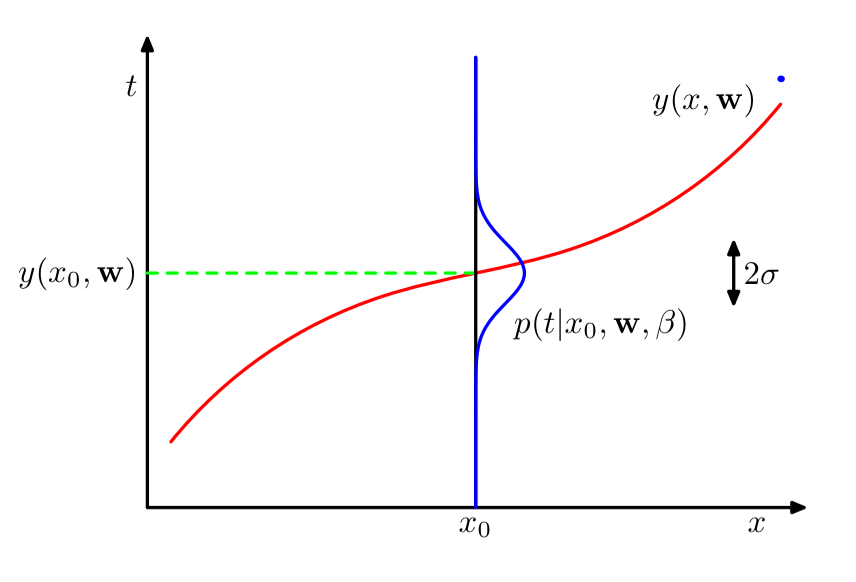
이제 각각의 데이터에 대해서 이를 정의해 놓았으니, 데이터 전체에 대해서는 각각의 데이터가 i.i.d라는 가정 하게 그냥 곱해주면 된다. 다음과 같이 말이다.
자, 이제야 뭔가 손에 잡히는 느낌이 든다(아닌가?!?)
자세히 보면 위 식이 likelihood 아닌가? 정의 그대로이다.
이제 위의 Probability를 최대화 하면 되는 것이다.
근데 product는 다루기 어려우니 만능 툴인 로그를 씌워 보자.
이때, 우리는 2가지 parameter에 대해서 위 식의 최대값을 구해야 한다. 첫번째가 $w$이고 두번째가 $\beta$이다.
우선 $\beta$부터 해보자면 다음과 같이 가능하다.
결국 이 미분 값을 0으로 만드는 값이 최대값일 것이므로 다음과 같이 식을 풀어낼 수 있다.
이제 $w$에 대해서 최대값을 구해보면 다음과 같다.
어..? 어디서 많이 본 것 같지만 일단 넘어가자. (실은 나중에 loss function 부분에서 한번 더 다루겠다.)
여기서의 최적화는 다양한 방법으로 시도할 수 있다.
이의 원리를 다시 한번 떠올려보자.
- 에러가 Gaussian Distribution을 따를 때,
- 주어진 데이터 𝐷를 우리의 model이 데이터를 잘 설명할 수 있다는 가설이
- 참일 것이라는 확률(확실성)을 높이는 과정
이것이 바로 우리가 진행한 것이다.
그렇다면, 이제 MAP를 활용해서 이를 구해보면 어떻게 될까?
Bayes’ Theorem에 따라 구하면 다음과 같이 작성 가능하다.
위 식에서 뭔가 낯설지만 익숙한 것이 보인다. 바로 $Pr(w|\alpha)$이다. 이것이 바로 “사전 확률”이다.
사전 확률 또한 우리가 모르지만, 일단 만능인 Gaussian 이라고 가정해 보자. (이 가정이 나름의 타당성을 갖춘다는 것을 알고 싶으면 확률 및 랜덤 변수를 조금 깊게 공부해 보자.)
그렇다면, 우리는 이를 통해서 최대 (로그)사후 확률을 마찬가지로 미분을 통해서 구해보면 다음과 같다.
이것도 뭔가 어디서 본 것 같은데..? 라고 생각한다면 당신은 멋진 사람 :)
이걸로 Bayesian Statistics에서 말하는 likelihood와 prior/posterior 확률이 어떤 개념인지 조금이라도 와 닿았으면 좋겠다 ㅎㅎ.
이 파트에서는 정보 이론을 매~~~~우 간단하게만 다루어볼 예정이다. 이것도 다룬다고 말하기도 부끄럽다고 할 수 있을 정도로만 다루도록 하겠다.
정보 이론은 “정보량”의 개념으로부터 시작한다. 이것이 현대에 들어서 통신, 패턴 인식 등 여러 분야에 사용되고 있다.
그리고 이러한 정보량의 평균을 “엔트로피”라고 부른다.
정보량은 다음과 같이 정의된다.
한가지 예를 들어 보겠다. 다음과 같이 정의되는 랜덤 변수가 있다고 가정해 보자.
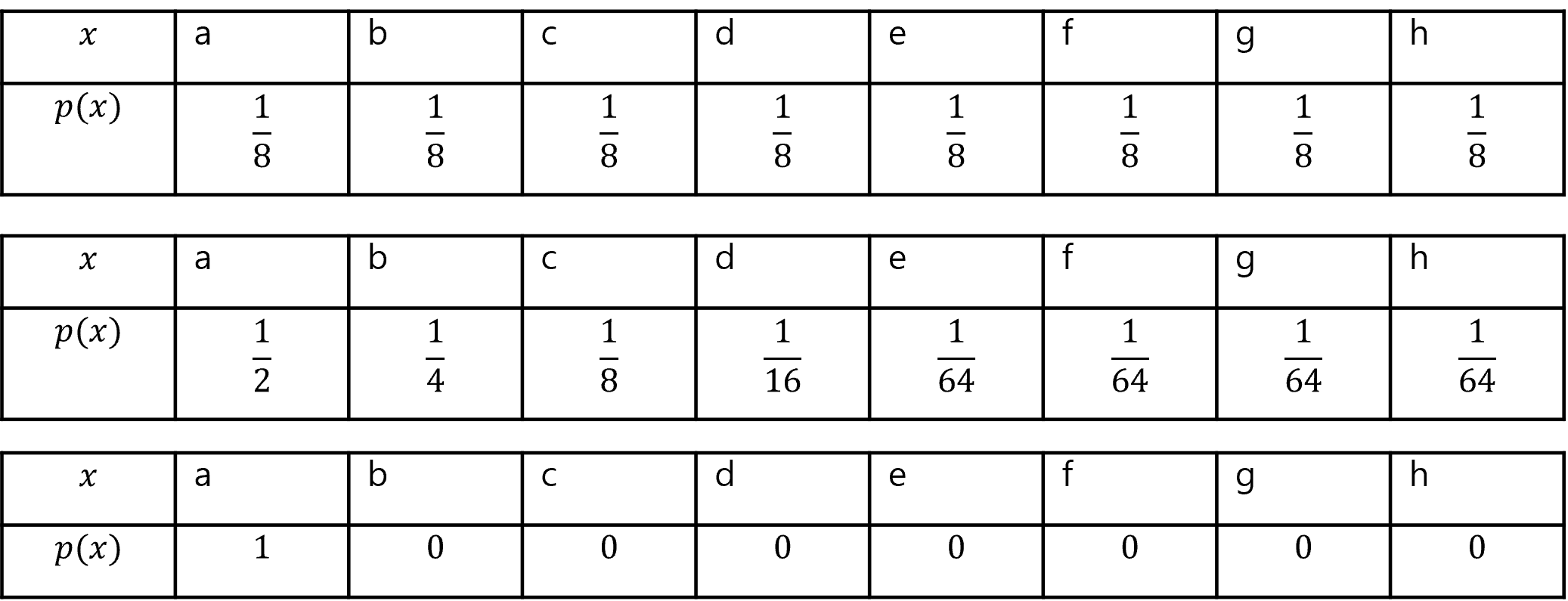
이의 엔트로피를 구해보면 다음과 같다.
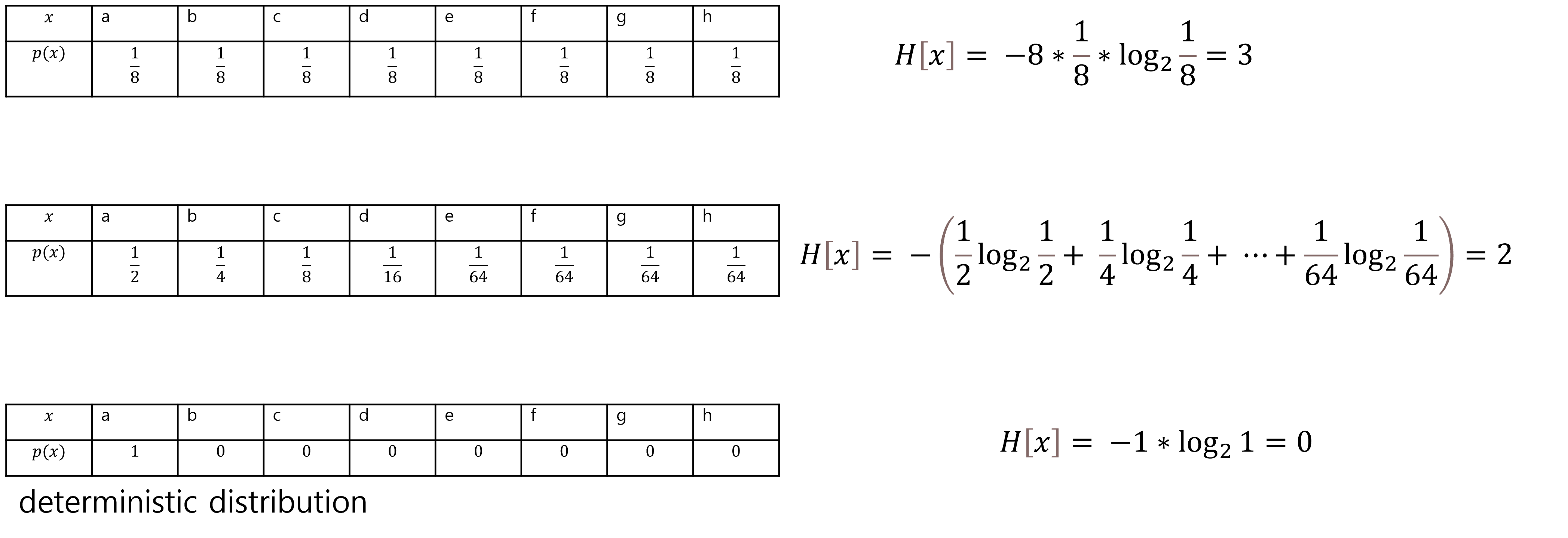
이 내용을 갑자기 왜 하느냐? 우리는 다른 2개의 확률분포의 상대적 엔트로피와 상호 정보량을 계산하여 2개의 확률분포의 차이를 정량화 할 수 있기 때문이다.
우선, 우리가 근사를 목표로 하는 확률 분포를 $𝑝(𝑥)$라고 해보자.
이를 근사하기 위해서 모델을 학습시켜서 확률 분포 $𝑞(𝑥)$를 얻어 냈다고 치자.
이때, $𝑞(𝑥)$를 통해서 얻어낸 정보는 원래 $𝑝(𝑥)$를 통해서 얻을 수 있는 정보와 상이할 것이고, 우리는 이에 추가로 필요한 정보량의 평균을 다음과 같이 구할 수 있을 것이다.
자, 그렇다면 우리는 대충 궤가 보인다. 우리가 결국 학습시켜야 하는 분포 $𝑞(𝑥)$와 정답인 분포 $𝑝(𝑥)$사이의 차이를 정량화 해주는 함수가 바로 이것인 것이다.
이를 “쿨백-라이브러리 발산”이라고 하며, 이를 통해서 우리는 두 확률 분포의 차이를 알 수 있는데,
자세히 보니, 뒤의 목표 분포의 엔트로피는 그냥 상수나 다름이 없다. 따라서 앞의 항만을 따서 따로 “Cross-Entropy”라고 하며, 다음과 같이 표현할 수 있다.
Gradient
이 파트에서는 대학교에서 Calculus를 배우지 않은 (배웠다 하더라도 다변수 함수의 미분 파트를 안 들은 이들) 사람들이 꼭 보아 주었으면 한다. Gradient의 기초 중의 기초를 다룰 예정이다.
우리는 이전 시간에 결국에는 미분을 구해서 가중치를 update하는 것이라고 배워왔다.
근데, 이때 “Gradient”라는 것에 대한 명확한 설명 없이, 그냥 하면 된다는 식으로 짚고 넘어갔던 기억이 난다.
우선, 함수에서 몇가지 예시부터 생각하고 넘어가자.
- $f: \mathbb{R}^1 \rightarrow \mathbb{R}^1$
- $f: \mathbb{R}^N \rightarrow \mathbb{R}^1$
- $f: \mathbb{R}^1 \rightarrow \mathbb{R}^N$
- $f: \mathbb{R}^N \rightarrow \mathbb{R}^M$
이때, $N,M \geq 2$이다.
$\mathbb{R}^1$을 따로 분리한 이유가 있다. 함수에서 입/출력이 벡터(또는 행렬)인 것과 입/출력이 Scalar인 것은 다소 상이한 과정을 도입해야 하기 때문이다. 우리는 이 중에서도 2번을 특히 중요하게 다룰 것이다.
이렇게 함수는 여러가지 형태가 있을 수 있는데 이때, 각각 정의역에 대한 미분이 어떻게 정의될까?
이 파트에서는 그 예시를 들어볼 것이다.
우선, $f: \mathbb{R}^N \rightarrow \mathbb{R}^1$ 에서의 경우를 보자. 일 변수 스칼라 함수의 경우는 빼겠다. 그걸 모르면 이걸 들을 자격이 없다.
우리는 이러한 함수를 vector-scalar함수라고 부르겠다.
이러한 함수의 미분은 다음과 같이 정의할 수 있다.
이렇게 정의되어 있을 때, 함수 $f$에 대한 Gradient는 다음과 같이 표현되고 정의된다.
여기서 만약 입력이 행렬이면 어떻게 되어야 할까?
즉, 다음과 같이 출력이 Scalar이고 입력이 벡터인 함수이다. (Matrix-Scalar함수)
Loss Function Examples
이 파트에서는 위에서 배운 수학적인 기초를 토대로 Loss function의 예시를 한번 볼 것이다.
우선 MSE부터 생각해 보자. 결국 MSE는 MLE/MAP를 이론적인 기저로 두고 있었다는 것을 위 글을 읽었다면 이해할 수 있었을 것이다. $equation 5$를 다시 한번 봐보자.
그렇다면 Cross-Entropy를 어떻게 사용할 것인가?
신경망에서는 이를 분류 문제를 어떻게 풀까? 우리는 Softmax 함수를 같이 사용하여 이를 해결할 수 있다.
먼저 softmax 함수부터 생각해 보자.
위 함수를 Neural Network에서 output layer의 각 출력 값을 확률 분포로 바꾸어 준다고 생각하면 된다. 실제로 모든 unit의 값을 다 더하면 1이 되니깐 말이다.
이제 이러한 확률 분포를 토대로 실제 우리가 원하는 target 확률 분포와의 거리를 구하는 과정을 Cross entropy로 진행할 수 있을 것이다. 다음과 같이 말이다.
이때, target 분포는 class에 따라 one-hot encoding이 되어 있음
이때, 이 함수를 미분하면 어떻게 될까? 다음을 한번 보자.
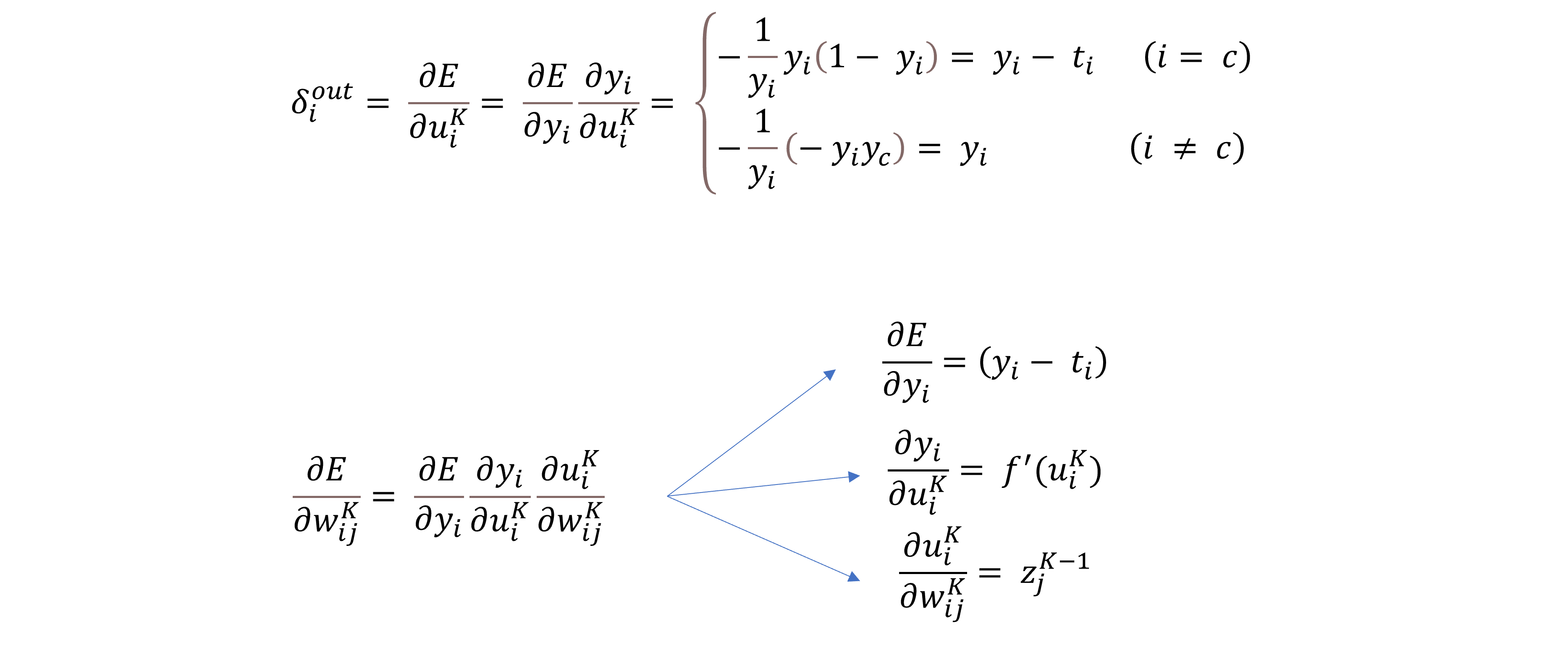
결국 형태가 One hot encoding이 되어 있다면, MSE와 딱히 다를 것이 없다는 것을 알 수 있다.
What is Optimizer?
이 파트에서는 위에서 배운 수학적 기초를 토대로 Optimizer가 어떻게 동작을 하는 놈들인지 배워 보도록 하겠다.
그래서 Deep learning에서의 Optimizer는 어떤 역할인지 알아보자. 결국 Deep learning은 해당 문제를 해결하는 것에 중심을 두고 있다. 이때, 우리는 특정한 문제를 해결한다고 했을 때, 특정 지표(ex. 정확도)를 최대화 한다는 것이다.
우리는 이때 정확도를 최대화 하기 위해서 데이터에서 얻을 수 있는 손실(Loss)를 최소화하는 것을 진행한다. 이는 기존 최적화와는 조금 다르다. 직접 지표를 최대화하는 것이 아닌, 간접적인 지표를 최소화하는 방향으로 가는 것이니 말이다.
그래서, 결국 Optimizer의 역할이 무엇인가?
다음과 같다.
이게 뭐냐? 즉 데이터에 대한 손실을 최소화 하는 것이다. 이것이 Optimizer 의 궁극적인 역할인 것이다.
이 문제는 1줄만 생각해 보면 간단해 보이지만 실은 겁나게 어렵고 복잡한 문제이다.
이 문제를 풀기 위해서 우리는 Gradient Descent라는 방법을 사용하는 것이다.
여기서 Gradient Descent의 수렴성을 설명하고 싶지만…. 강의에서는 생략하도록 하겠다. 더 자세히 알고 싶으면 Talyor 급수를 키워드로 잘 찾아보기를 바란다. 만약 나중에 시간이 된다면 다시 다루어 보도록 하겠다.
이쯤에서 미니 배치의 의미를 설명하고 가도록 하겠다.
이 것은 다음 그림으로 설명이 될 수 있다.
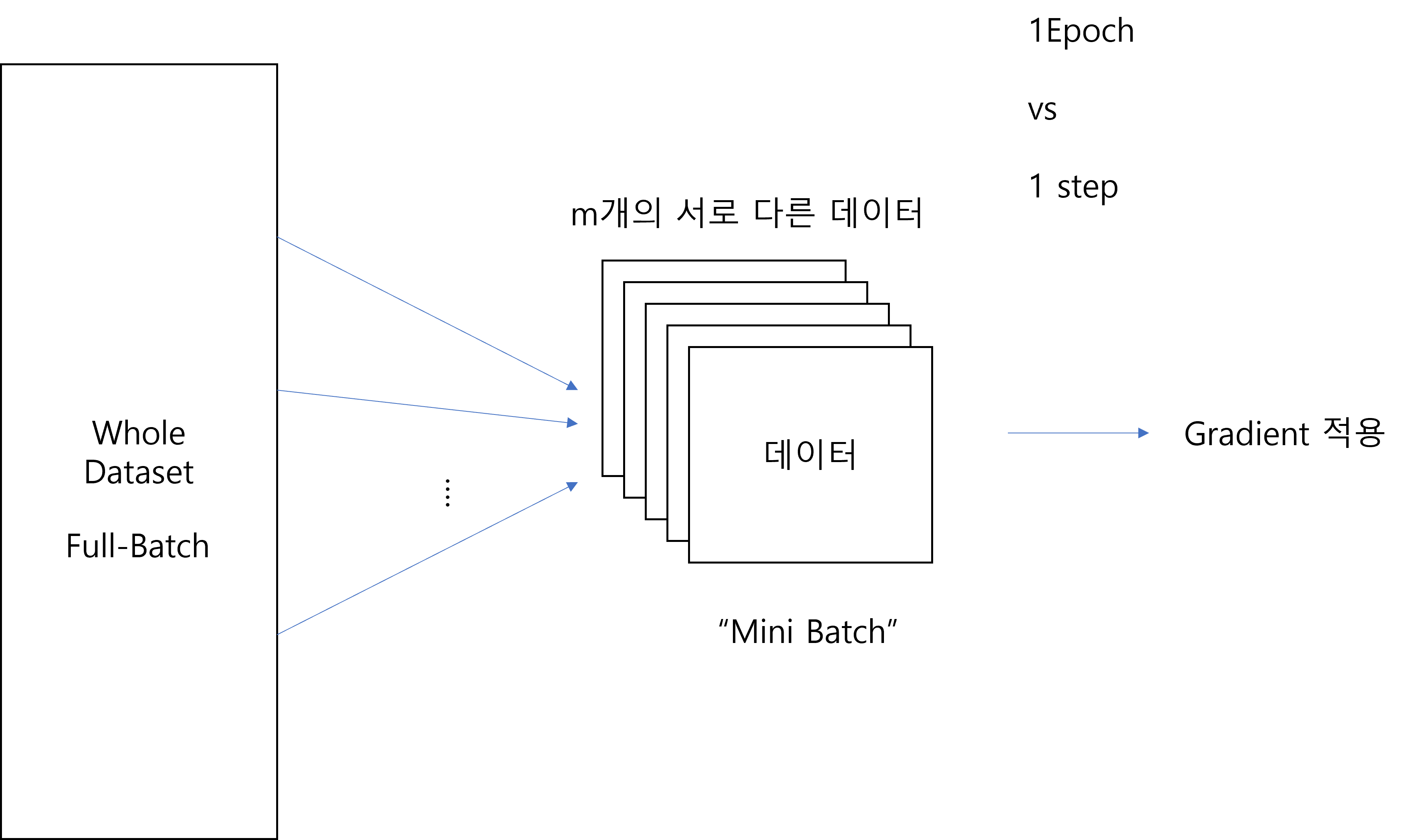
~역시 필자는 필자 스스로 생각해도 발 그림이다. 당도췌 어떤 정신머리로 이딴걸 그리는지 모르겠다.~
자 각설하고, 전체 데이터에서 정해진 Batch Size 만큼을 뽑아서 만든 데이터를 Mini Batch라고 한다. 이를 신경망에 넣어서 Feed Forward를 하고 Back propagation 연산을 하면서 가중치를 업데이트한다. 이것이 학습의 1개의 step이다. 그리고 이 mini batch set으로 전부의 데이터를 학습 했을때, 그것을 1개의 epoch이라고 한다. (통상적으로) 이렇게만 간단하게 생각하고 나머지는 Optimizer 별로 따로 생각하면 편할 것이다.
Optimizer examples
이 파트에서는 Optimizer의 종류가 어떤 것들이 있는지 알아보도록 하겠다.
- Stochastic Gradient Descent
이 Optimizer는 가장 간단한 Optimizer라고 생각해도 된다. 위에서 설명한 대로, 간단하게 Mini Batch를 뽑아서 Update를 진행한다.

- Adagrad
이 방법은 이전에 사용했던 gradient들을 축적해서 사용하는 방법이다. gradient를 원소별로 제곱해서 step별로 더해가는 행렬을 하나 만들고, 그 행렬을 update할때 gradient에 원소별로 곱해주는 것이다. 제목 그대로 Adaptive gradient 방법인 것이다.

- RMSProp
이 방법은 위의 Adagrad 방법에서 조금 더 나아가, gradient를 더해나갈때 가중치를 두는 방법이다.

- Adam
현재 가장 많이들 쓰는 Optimizer이다. 이것도 별거 없다. RMSProp 처럼 가중합을 진행하는데, 이번에는 원소별로 제곱하지 않은 gradient도 누적 합을 저장해서 사용한다. 자세한 것을 수식을 보면 바로 감이 올 것이다.

이걸로 Optimization 파트 A는 끝이 났다. 다음 파트는 위에서 배운 것들을 구현하면서 찾아 오도록 할 것이다.